
Help & Knowledge Base
Customizing Result File Names
Special keywords can be used as placeholders in the output file names, to be replaced with dynamic values during the execution.
A trivial example is prefixing each document with the page number, when splitting.
[CURRENTPAGE]
A reference to the current page number in the input document.
Example: [CURRENTPAGE###] will generate filesnames like 001.pdf, 002.pdf.
Example: [CURRENTPAGE##] generates 01.pdf, 02.pdf, etc.
[TIMESTAMP]
Ensures unique output filenames, being replaced with current date & time.
[FILENUMBER]
Ensures unique output filenames, replaced with a file number according to the output order.
Example: [FILENUMBER###] generates 001, 002
Example: [FILENUMBER13] starts with the counter at 13, generating 13, 14,
etc.
[BASENAME]
Does not ensure unique output filenames, and it must be used together with other placeholders ensuring unique names. It is replaced with original name of the input document, without the extension.
Example: [CURRENTPAGE]_[BASENAME] would generate 1_input-file.pdf, 3_input-file.pdf,
etc.
[BOOKMARK_NAME]
This pattern is replaced by current bookmark's name. Only applicable in the "Split by bookmarks" tool.
[BOOKMARK_NAME_STRICT]
Same behavior as [BOOKMARK_NAME] with the difference that non-alphanumberic characters are
removed.
Example: [CURRENTPAGE]-[BOOKMARK_NAME] would generate 1-Introduction.pdf, 4-Chapter
1.pdf, etc.
[TEXT]
This pattern is applicable only in the "Split by text" tool. It is replaced with the text found in the page area selected.
Example: [CURRENTPAGE]-[TEXT] would generate 1-Invoice 3456789.pdf, 4-Invoice
234567.pdf, etc.
[TEXT1], [TEXT2], etc.
This pattern is applicable only in the "Rename" tool. It is replaced with the text found in the selected area.
Example: [TEXT2]-[TEXT1] would generate John Doe-Invoice 3456789.pdf, Jane Doe-Invoice
234567.pdf, etc.
Sejda Desktop Enterprise Install
To deploy Sejda Desktop in an enterprise environment using a pre-configured volume license key use this command:
msiexec /i sejda-desktop_x.y.z_x64.msi LICENSE_KEY="1234-ABCD-1234-ABCD"
Any options provided will be configured machine-wide and will apply for all users on the system.
| LICENSE_KEY | License key | LICENSE_KEY="1234-ABCD-1234-ABCD" |
| LOCALE | UI language | en, es, de, fr,it or pt |
| UPDATE_CHECK | Disables checking for new versions | UPDATE_CHECK="false" |
| DISABLED_FEATURES | List of features to be disabled | DISABLED_FEATURES="edit.whiteout" |
| EULA_ACCEPTED | Accept EULA and no longer prompt on first use | EULA_ACCEPTED="true" |
| AUTO_REPORT_ERRORS | Configure automated error reporting and no longer prompt on first use | AUTO_REPORT_ERRORS="false" |
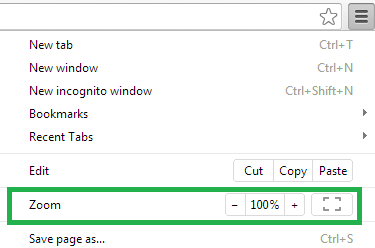
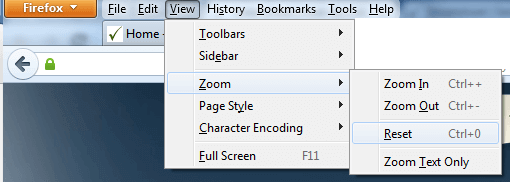
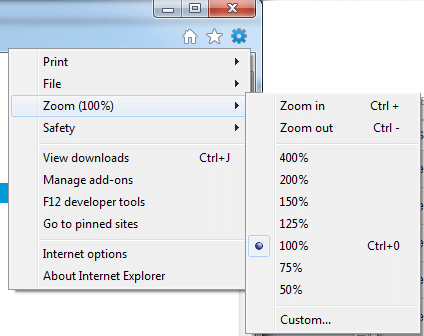
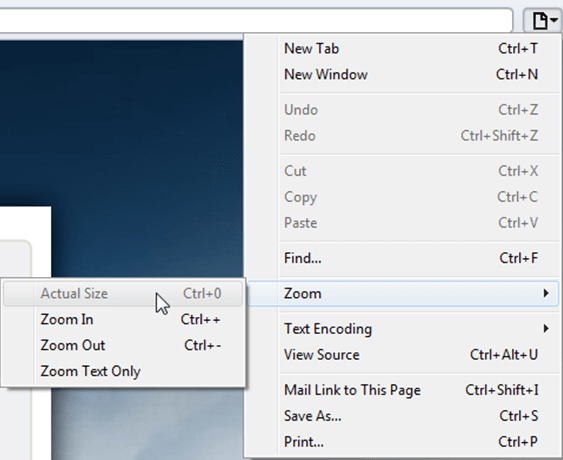
Resetting Browser Zoom
Choosing a zoom level of anything other than 100% (the default) can cause problems in pages where we render PDF pages.
If you are warned about it, reset the browser zoom to 100%.
The quickest way to return your browser to this zoom setting is to use the keyboard shortcut Ctrl + 0 on Windows or Cmd + 0 on Mac.
Additional browser-specific instructions for changing the zoom level are detailed below.
Chrome
Firefox
Internet Explorer
Safari
Sejda Desktop - Loading local fonts failed
Sejda Desktop fails to load the fonts installed on your system?
Windows 7: Please install "Platform update for Windows 7 SP1": https://support.microsoft.com/en-us/kb/2670838.
Linux: Please install libfontconfig-dev: sudo apt-get install libfontconfig-dev
Sejda Desktop - Add your fonts
Sejda Desktop can use your custom fonts when editing PDF documents.
1) Install the font on your system. See help for Windows or Mac.
2) Open Sejda Desktop, then open a PDF document with the Editor.
3) Type text on the page. From the context menu select "Fonts > More fonts".
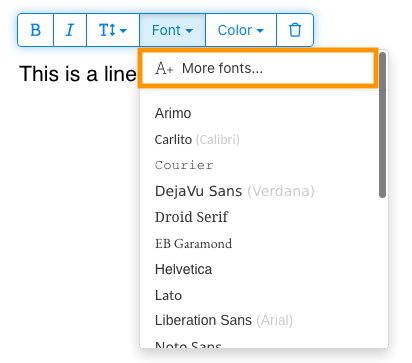
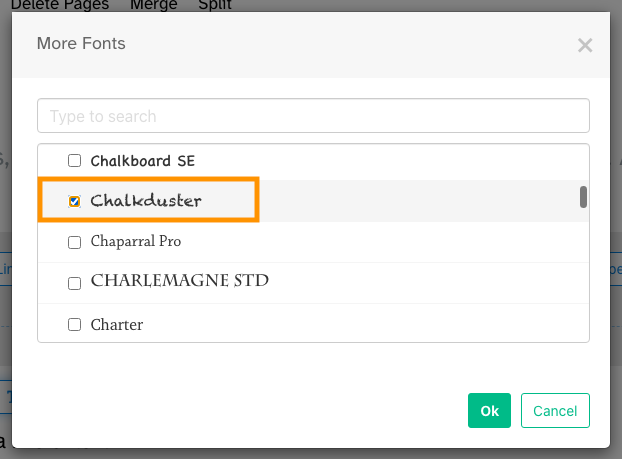
4) Select the font you would like to use and click "OK".
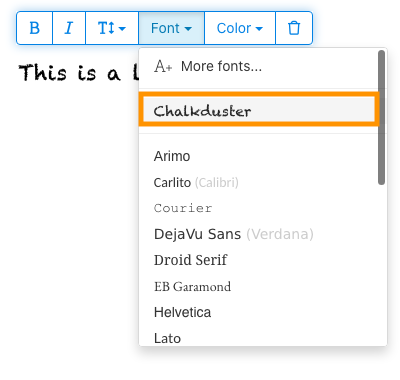
5) Click on the newly added font to use it for your text.
How long does it take for a refund to be processed?
It can take anywhere from 5-10 business days for a refund to show up on your bank account.
In some cases, the refund might be processed as a reversal, meaning the original payment will disappear from the account statement entirely and the balance will reflect as though the charge never occurred.
If you do not see the refund after 10 business days and you are still seeing the original charge on your bank statement, please reach out to support for more information.
How can you delete your FastSpring data?
If you've placed an order through FastSpring, our online authorized reseller & merchant of record, you can send your data erasure request to privacy@fastspring.com.
Malwarebytes interfering with Sejda Desktop?
Do you have Malwarebytes installed?
Please try temporarily turning Malwarebytes off and see if that solves the problem: Instructions here
You can report this problem with Malwarebytes: Report false positive
Could not convert: Page uses CAPTCHAs
The website you are trying to convert uses CAPTCHAs to block automated robots (such as our converter) from visiting their website.
There is no work around this.
See if the browser extension helps with your use-case:
HTML to PDF browser-extension
Install Linux OCR engine
Sejda Desktop does not ship with an embedded OCR engine on Linux, it uses the one available on the system.
To install an OCR engine, please run the following command:
sudo apt-get install -y tesseract-ocr tesseract-ocr-all
Once the command completes, return to Sejda Desktop and run your OCR task again.
Install Linux OCR language data
The OCR engine is installed successfully, but it is missing language data.
To install language data, please run the following command:
sudo apt-get install -y tesseract-ocr-all
About 667M of data will be downloaded and installed.
Once the command completes, return to Sejda Desktop and run your OCR task again.
Ich werde aufgefordert, das Besitzer-Passwort einzugeben
Warum werde ich nach einem Passwort gefragt?
Einige PDF-Dokumente haben Sicherheitseinstellungen, die bestimmte Aktionen einschränken, wie Drucken, Text kopieren, Bearbeiten oder Anmerkungen hinzufügen. Diese Einschränkungen werden vom Ersteller des Dokuments implementiert, um zu kontrollieren, wie der Inhalt verwendet und geteilt wird.
Wenn wir feststellen, dass ein PDF diese Einschränkungen hat, fordern wir dich zur Eingabe des Besitzer-Passworts auf. Die Eingabe dieses Passworts entsperrt das Dokument und gewährt vollen Zugriff auf alle Funktionen und Berechtigungen. Dieser Schritt stellt sicher, dass nur autorisierte Personen die vom ursprünglichen Autor festgelegten Einschränkungen ändern oder entfernen können.
Was ist ein Besitzer-Passwort?
Ein Besitzer-Passwort wird vom Ersteller des PDFs festgelegt, um unbefugte Änderungen am Dokument zu verhindern. Es unterscheidet sich von einem Benutzer-Passwort, das das Öffnen des Dokuments insgesamt einschränkt. Wenn du das Besitzer-Passwort hast, bedeutet das, dass du volle Berechtigung für das Dokument hast.
Was ist, wenn ich das Besitzer-Passwort nicht habe?
Wenn du das Besitzer-Passwort nicht hast, hast du weiterhin eingeschränkten Zugriff basierend auf den im PDF festgelegten Einschränkungen.
Um vollen Zugriff zu erhalten, besorge dir eine entsperrte Version des Dokuments.
Wie kann ich vermeiden, das Besitzer-Passwort jedes Mal wiederholt eingeben zu müssen?
Du kannst ein PDF-Entsperr-Tool verwenden, um die Berechtigungseinschränkungen aus deinem Dokument zu entfernen. Das machst du nur einmal. Dann wirst du nicht mehr nach dem Besitzer-Passwort für das Dokument gefragt.
Öffne das PDF-Dokument in Google Chrome, drücke Strg+P zum Drucken, wähle oben rechts als 'Ziel' 'Als PDF speichern' und klicke dann auf 'Speichern'.
Wird der Kauf eines kostenpflichtigen Plans das Problem lösen?
Nein, du wirst auch dann nach dem Besitzer-Passwort gefragt, wenn du einen kostenpflichtigen Plan bei uns hast.
Kannst du mir das Besitzer-Passwort sagen?
Nein, wir kennen das Besitzer-Passwort für deine Dokumente nicht. Das Besitzer-Passwort wurde von der Person gewählt, die dein Dokument erstellt hat, und unterscheidet sich von deinem Anmelde-Passwort.
Ich kann ein gescanntes Dokument nicht bearbeiten oder konvertieren
Warum können gescannte Dokumente nicht bearbeitet oder konvertiert werden?
Wenn du ein physisches Dokument scannst, um ein PDF zu erstellen, erfasst der Scanner ein Bild jeder Seite. Dieser Prozess wandelt Text, Grafiken und Layout in eine einzige Bilddatei um, die in das PDF eingebettet ist. Im Gegensatz zu Standard-PDFs, bei denen Text als einzelne Zeichen und Zeilen gespeichert ist, die ausgewählt, kopiert und bearbeitet werden können, behandeln gescannte PDFs jede Seite als ein großes Bild.
Da der Text in einem gescannten PDF Teil eines Bildes ist, können PDF-Editoren ihn nicht direkt erkennen oder ändern. Die Software sieht nur eine Ansammlung von Pixeln, keine unterscheidbaren Buchstaben oder Wörter. Dies macht es unmöglich, Textabsätze zu bearbeiten oder Änderungen vorzunehmen, wie du es in einem normalen, textbasierten PDF-Dokument tun würdest.
Wie stellt man fest, ob ein Dokument ein Scan ist?
Eine Möglichkeit festzustellen, ob ein PDF ein gescanntes Bild ist, besteht darin, es mit einem PDF-Viewer zu öffnen und zu versuchen, den Text mit der Maus auszuwählen. In einem bearbeitbaren PDF kannst du Text hervorheben, indem du mit dem Cursor darüber klickst und ziehst. Wenn du keinen Text auswählen kannst und sich die gesamte Seite wie ein einziges Bild verhält, handelt es sich wahrscheinlich um ein gescanntes Dokument.
Hinweis: Einige gescannte Dokumente werden mit Optical Character Recognition (OCR) verarbeitet, um 'durchsuchbare' Scans zu werden, bei denen Text ausgewählt und gesucht werden kann. Diese Dokumente sind jedoch immer noch Scans und können nicht wie Standard-PDFs bearbeitet oder konvertiert werden.
Ich bin sicher, mein Dokument ist kein Scan
Einige Dokumente ähneln Scans, da ihr Inhalt als Bilder auf jeder Seite eingebettet ist. Dies kann bei Dokumenten passieren, die aus Screenshots erstellt wurden oder wenn Text in Pfade umgewandelt wurde, anstatt als bearbeitbarer Text eingebettet zu sein.
Obwohl dies technisch keine Scans sind, funktionieren sie ähnlich. Leider unterstützen wir auch das Bearbeiten oder Konvertieren dieser Art von Dokumenten nicht.
Wird der Kauf eines kostenpflichtigen Plans das Problem lösen?
Nein, ein Upgrade auf einen kostenpflichtigen Plan ermöglicht es dir nicht, gescannte Dokumente zu bearbeiten oder zu konvertieren. Das Bearbeiten oder Konvertieren von Scans wird unabhängig von deinem Abonnementstatus nicht unterstützt.
Ich bin sicher, dass ich dieses Dokument zuvor bearbeiten konnte
Wir haben das Bearbeiten oder Konvertieren gescannter Dokumente nie unterstützt. Wenn du das Dokument zuvor bearbeiten konntest, wurde es wahrscheinlich anders als das aktuelle Dokument in PDF exportiert.
Sejda Desktop schlägt aufgrund von Berechtigungen fehl
Es gibt 2 häufige Ursachen für diesen Fehler: unzureichende Berechtigungen oder Antivirus-Störungen.
Unzureichende Berechtigungen: Möglicherweise musst du Sejda Desktop mit Administratorrechten ausführen. Klicke mit der rechten Maustaste auf die App, wähle dann 'Mehr' > 'Als Administrator ausführen'.
Antivirus- oder Sicherheitssoftware: Versuche, dein Antivirenprogramm vorübergehend zu deaktivieren, um zu überprüfen, ob dies zur Lösung des Problems beiträgt.